Me mudo...
Me mudo a otro blog, compartido on FALEVIAN
posted by Mario Castro @ 5:20 PM
0 comments
![]()
En este blog recojo algunos trucos, ideas, reflexiones y atajos para resolver algunos problemas relacionados con la simulación en ciencia, la administración de sistemas Linux, y otras cosas por el estilo.
Y a la vuelta, novedades (una fusion con otro blog).
posted by Mario Castro @ 11:05 AM
0 comments
![]()
La Informática es una gran ciencia. En contra de lo que podemos pensar como usuarios, es una disciplina bien estructurada, en ocasiones infinitamente mejor pensada que la arquitectura o la ingeniería civil. Y sin embargo, las casas apenas se caen y los sistemas informáticos apenas se sostienen.
posted by Mario Castro @ 2:03 PM
3 comments
![]()
He visto esta noticia que me ha dejado ciertamente perplejo.
posted by Mario Castro @ 8:04 PM
2 comments
![]()
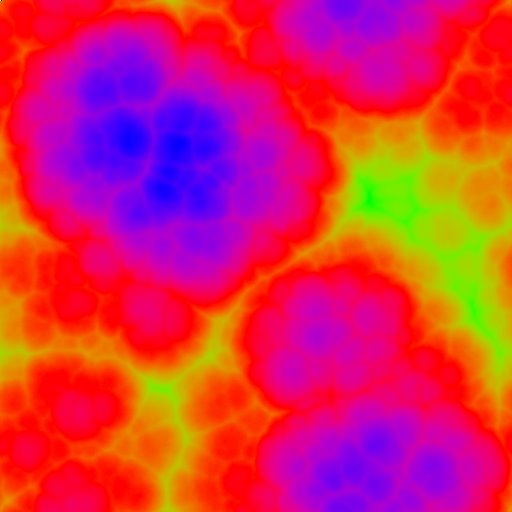
En mi primer post (bueno el segundo) os conté cómo crear una imagen bidimensional a partir de un fichero de datos. En esta entrega os contaré como hacer lo mismo con color.
#!/bin/bash
if [ $# -ne 3 ]; then
echo "Sintaxis: $0 Nx Ny fichero_de_entrada "
exit
fi
awk '
BEGIN{max=-100000000; min=100000000;}
{
for (i=1;i<=NF;i=i+1){ if (max<$i) max=$i; if(min>$i) min=$i;}
}
END{print max,min}' $3 | awk -v Nx=$1 -v Ny=$2 '
BEGIN{print "P3\n#\n\n" Nx,Ny "\n255 255 255"}
NR==1 {
max=$1;
min=$2;
}
{
for(i=1;i<=NF;i=i+1) {
val=int(($i-min)*255/(max-min))
print val,val,val
}
}' - $3 >$3.ppm
#!/bin/bash
if [ $# -ne 3 ]; then
echo "Sintaxis: $0 Nx Ny fichero_de_entrada "
exit
fi
awk '
BEGIN{max=-100000000; min=100000000;}
{
for (i=1;i<=NF;i=i+1){if (max<$i) max=$i; if(min>$i) min=$i;}
}
END{print max,min}' $3 | awk -v Nx=$1 -v Ny=$2 '
BEGIN{
for(i=0;i<128;i++) {
b[i]=int(255-2*i*i/128); g[i]=int(255-2*(128-i)*(128-i)/128); r[i]=0;}
for(i=0;i<128;i++) {
b[i+128]=0; g[i+128]=int(255-2*(i)*(i)/128); r[i+128]=int(255-2*(128-i)*(128-i)/128); }
for(i=0;i<=255;i++) {
if(r[i]<0) r[i]=0; if(g[i]<0) g[i]=0; if(b[i]<0) b[i]=0;
if(r[i]>255) r[i]=255; if(g[i]>255) g[i]=255; if(b[i]>255) b[i]=255;}
print "P3\n#\n\n" Nx,Ny "\n255 255 255"
}
NR==1 {
max=$1;
min=$2;
}
{
for(i=1;i<=NF;i=i+1) {
val=int(($i-min)*255/(max-min))
print r[val],g[val],b[val]
}
}' - $3 >$3.ppm
for(i=0;i<128;i++) {
b[i]=int(255-2*i*i/128); g[i]=int(255-2*(128-i)*(128-i)/128); r[i]=0;}
for(i=0;i<128;i++) {
b[i+128]=0; g[i+128]=int(255-2*(i)*(i)/128); r[i+128]=int(255-2*(128-i)*(128-i)/128); }

posted by Mario Castro @ 11:09 AM
0 comments
![]()
Hoy voy a hablar de vim (la versión mejorada de vi). vim tiene todo lo bueno de vi, pero además permite una serie de extensiones, plugins y macros que quitan el aliento. En otra ocasión os hablaré de los plugins y os recomendaré alguno. Mientras podéis disfrutar de todo sobre vim en el enlace
" Los comentarios van precedidos por unas comillasY ahora mi parte favorita, los "mapeos" de teclas a comandos.
" La siguiente línea cambia el tamaño por defecto del tabulador a 3
set tabstop=3
" mantiene 50 líneas de historia de comandos en una sesión vim
set history=50
" Los tres siguientes permite usar el comando externo 'par' quePara finalizar, os hablaré de los pliegues o 'folds'. Son agrupaciones de varias líneas en una única línea que se despliega con un comando. Para más información sobre los pliegues podeís poner (dentro de vim) :help folds.
" viene con casi todas las distribuciones linux (salvo Suse) e incluso
" con cygwin y que permite manipular párrafos de texto
" El siguiente simplemente toma un párrafo (considerando párrafo hasta
" las siguiente línea vacía) y lo ajusta a 78 columnas simplemente pulsando
" F3
map <F3> <Esc>!}par -w78 <CR>
" El siguiente hace lo mismo pero para un selección hecha en
" modo visual (con el comando v), de ahí la v de 'vmap'
vmap <F3> !par -w78 <CR>
" Por último, pulsando F4 ajusta el texto a 78 columnas indentando por
" los dos extremos (añadiendo espacios si fuese necesario)
map <F4> !}par -j1 -w78 <CR>
" imap hace referencia a comandos en modo 'insertar'. El siguiente
" comando ayuda a escribir textos en LaTex. Si escribes la palabra
" itemize y pulsas (en modo insertar) F4 te crea el begin y end
" correspondientes.
imap <F4> <Esc>bi\begin{<Esc>$a}<Esc>yypwdwiend<Esc>O
" Y ya que estamos con Latex, aquí tenéis algo cómodo
" F5 guarda el fichero actual y lo compila
map <F5> :w!<CR>:!latex %<CR><CR> <CR>
" F6 invoca al comando xdvi
map <F6> :!xdvi %<.dvi&<CR><CR>
" F7 crea el postscript correspondiente (en compatibilidad PDF) y llama
" al programa "gv"
map <F7> :!dvips -P pdf -G0 %<.dvi >& /dev/null <CR><CR>:!gv %<.ps &<CR><CR>
" Por último, F8 crea un pdf y llama al comando xpdf
map <F8> :!ps2pdf %<.ps<CR>:!xpdf -z page %<.pdf &<CR><CR>
map F za
map <S-F12> :set foldmarker=\{,\}<CR> :set foldmethod=marker<CR>
map <S-F12> :set foldmarker=\\begin,\\end<CR> :set foldmethod=marker<CR>
posted by Mario Castro @ 12:35 PM
4 comments
![]()
El truco de hoy consiste en lo siguiente. Supongamos que hemos hecho una simulación de un problema en dos dimensiones, o en una pero queremos representar en una figura el espacio (eje x) y el tiempo (eje y). Podemos integrar una rutina en nuestro código (lo cual lo ralentiza) o podemos crear la imagen mediante un software de visualización (por ejemplo MATLAB).
#!/bin/bash
if [ $# -ne 3 ]; then
echo "Sintaxis: $0 Nx Ny fichero_de_entrada "
exit
fi
awk '
BEGIN{max=-100000000; min=100000000;}
{
for (i=1;i<=NF;i=i+1){
if (max<$i) max=$i; if(min>$i) min=$i;
}
}
END{print max,min}' $3 | awk -v Nx=$1 -v Ny=$2 '
BEGIN{print "P2\n#\n\n" Nx,Ny "\n65535"}
NR==1 {
max=$1;
min=$2;
}
{
for(i=1;i<=NF;i=i+1)
print int(($i-min)*65535/(max-min))
}' - $3 >$3.pnm
posted by Mario Castro @ 2:27 PM
5 comments
![]()
Espero poder dedicar algo de tiempo a este blog y que os resulte de utilidad. Algunas de las cosas que publicaré me han costado algo de tiempo aprenderlas (por mi ineptitud) y espero que os resulten de utilidad.
posted by Mario Castro @ 1:34 PM
2 comments
![]()